Features
Koverse stores and secures complex and sensitive data for search, analytics, AI, and application development.
SINGLE PLATFORM
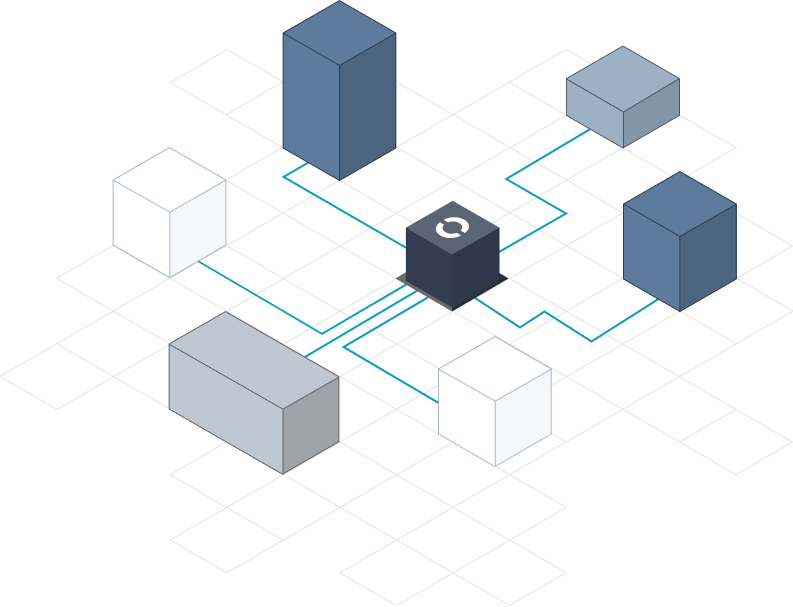
Physically Co-locate All Types of Data
Data is “secured-on-write”, i.e., immediately protected at ingestion. Any kind of data—structured or unstructured, streaming or static—can be ingested in its raw form without ETL, retaining the original structure of data. Preservation of the raw data provides the greatest flexibility to deploy that data for additional purposes.
Koverse supports search, analytics, AI, and application development across all data with precise access control enforcement to ensure that users can see and use only authorized data.
Key Benefit: Eliminate data silos while keeping data secure. Use all types of data as soon as available to make an immediate impact on your operation.
INTELLIGENCE-GRADE SECURITY
Logically Secure Data of Mixed Sensitivity with ABAC
Organizations commonly segregate sensitive data, such as classified, personal, or company-confidential data, into separate data silos. With Koverse’s NSA-modeled multi-level security options, including unique attribute-based access controls (ABAC), data segregation is no longer necessary. Access controls are uniformly enforced across search, analytics, and external API access. This functionality enables enforcement of fine-grained access control for the most demanding use cases.
Access controls can be applied at the following:
- Dataset level
- Column level
- Attributed-based row level
- Document/file-level and more
Koverse can support an unlimited number of distinct security attributes and multi-attribute security combinations to support the most complex access control requirements. Users without the proper authorization do not even know of the existence of unauthorized data.
All data is encrypted while stored in the platform and in transit. Specific columns can be masked with encryption or hidden completely.
Key Benefit: Increase the value and use of all data, particularly of mixed sensitivities, by ensuring the use of only authorized data. Lower costs and streamline operations by co-locating and logically separating data.
Integrate with Existing Access Control Systems
Koverse integrates with existing enterprise authentication and authorization systems to provide a seamless experience for administrators and end users. Access control integrations include Microsoft Active Directory, Okta, and many others.
Key Benefit: Enforce your enterprise access controls on data in Koverse.

OPERATIONAL AGILITY
Add New Data and Sources Quickly
Koverse enables rapid ingestion of data in its raw form without ETL. KDP uses schema discovery algorithms to identify the fields present in the data. Then Koverse presents profiles on those fields so users and admins can quickly get a sense for what information each dataset contains. All data is indexed and can be immediately searched via the API and plugged into new or existing analytic workflows. Indexing policies are completely configurable to promote optimization of costs vs. performance.
Key Benefit: Faster integration of new and updated datasets to provide relevant information quickly.
Enable High-Availability Search Across All Data
Koverse provides configurable, manageable, and unique indexing policies to optimize performance and control costs. A user-friendly UI enables indexes to be configured for all fields or a small subset of fields. Indexes are managed on a per-dataset basis and can be changed before, during, and after the data is loaded. For changes made after data is loaded, Koverse seamlessly and efficiently recomputes the indexes for historic data to support low-latency search. Index size can be easily managed through configurable automatic age-off.
Koverse’s multi-dimensional indexing capability enables not only efficient geo-temporal queries, but also queries that include other arbitrary fields. This functionality enables more complex real-time analytic applications to include situational awareness, AI, and other predictive applications.
Key Benefit: Quick response capabilities in support of the mission. Configurable optimization of performance and costs.
Apply Analytics and Data Science
Koverse enables rapid development of new solutions, including AI, predictive analytics, and more. Koverse can support analytics built on popular technologies such as Apache Spark, Python, and Java. Analytic developers, data engineers, and data scientists can leverage the tools that they already use to develop analytics and deploy them in Koverse. This saves months of development time for developers since they can focus on the mission instead of creating infrastructure.
Key Benefit: Adapt to new data and new operational requirements quickly.
Integrations, Automation, and Web Apps
Koverse has numerous native integrations available for use in minutes, including built-in industry standard integrations with Apache Kafka, Amazon S3, and Tableau JDBC. Koverse also has an extensive array of application interfaces (APIs) that enable easy custom integration with data sources, sinks, and web applications. In addition, all of Koverse’s functionality can be fully automated via the Automation API.
Learn more about Koverse Integration API, including sources, normalizations, field maskers, authentication, and authorization.
Key Benefit: Greater agility and faster time to value for your solutions.
Questions? Ready to get started?
We invite you to learn about how Koverse delivers strategic value by efficiently managing complex and sensitive data.