
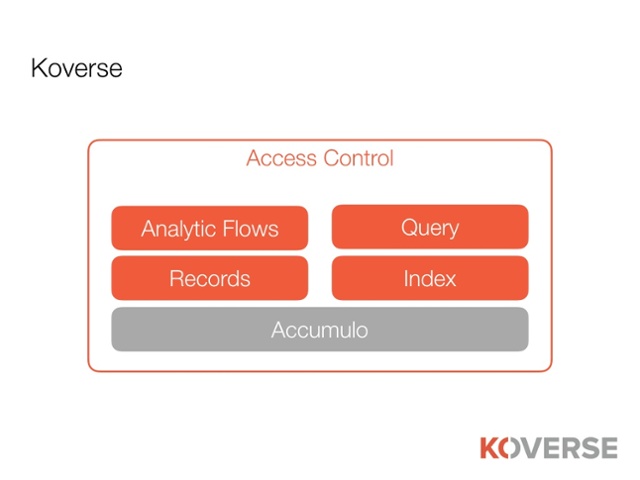
Koverse enables organizations to leverage their unique domain expertise and data to build scalable, secure and high-performing data-driven solutions. Koverse brings together scalable data storage, cell-level security, indexing and analytical data processing so developers and data scientists can build any solution to serve answers to thousands of end users.
Koverse is built on a foundation of proven open source technologies including Apache Hadoop, Apache Spark, and Apache Accumulo. These tools can be integrated for a variety of use cases. By using Koverse, teams can avoid costly and risky engineering to integrate these components and allows them to focus on what data to bring in, which questions to ask, and with whom the answers should be shared.
History
In 2008, Koverse Chief Product Officer and co-founder Paul Brown was working at the National Security Agency and led a broad effort to leverage new, highly scalable technologies, which included finding a way to organize and secure large data sets while providing the ability to search the data. As the solution to that problem, Koverse CTO and co-founder Aaron Cordova, as a member of Paul’s team, created Apache Accumulo.
Accumulo has had a massive impact on how information and data are managed and controlled throughout the intelligence and defense communities. In 2011, it became an open source project managed by the Apache Foundation. Today Accumulo continues to be the go-to data store for organizations that demand extremely high performance and scalability with a high degree of control over data security.
Introduction to Accumulo
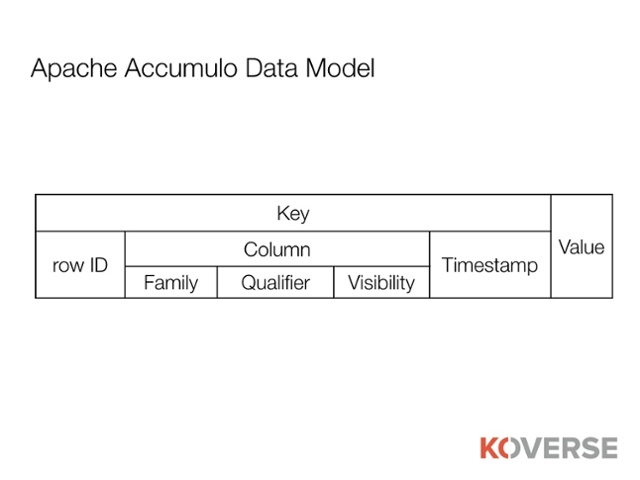
Accumulo is a highly scalable and secure data store based on Google’s BigTable design. Unlike a relational database, Accumulo does not support reading and writing data using SQL statements. Rather, it provides a low-level API for writing data as key-value pairs in tables. These key-value pairs are stored in order, sorted by the key, and applications can look up and scan one or more key-value pairs. Because the data is sorted by the key, lookups can be done in less than a second, even when a table contains trillions or more key-value pairs.
Accumulo automatically partitions tables and distributes partitions to multiple servers. It also recovers from server failures automatically, so that a very large amount of data can be managed on affordable hardware.
Cell-Level Security
Accumulo includes a novel feature for securing individual data elements, sometimes referred to as ‘cell-level security’. The name derives from the fact that Accumulo allows data to be organized into rows and columns, much like a conventional relational database, but does not restrict access control policies to either applying to entire rows or entire columns. Rather, Accumulo allows an individual ‘cell’ of a particular row, at a particular column, to have its own security label which controls who is allowed to read it.
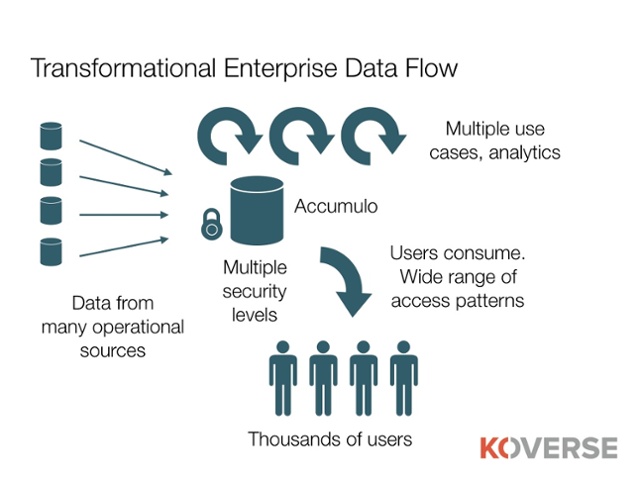
Cell-level security provides control over data access so that highly sensitive and non-sensitive data sets can be stored together in a common system without exposing any information to unauthorized individuals. The ability to co-host all data sets in this way enables a single system to serve the needs of all the groups in an organization. At the same time, cell-level security makes it possible, often for the first time, for analytics to process multiple data sets at once, resulting in breakthrough insights.
In 2012, Paul and Aaron co-founded Koverse Inc. with the mission of helping more organizations achieve the same transformational success by building a software platform that provides crucial functionality for using Accumulo in production.
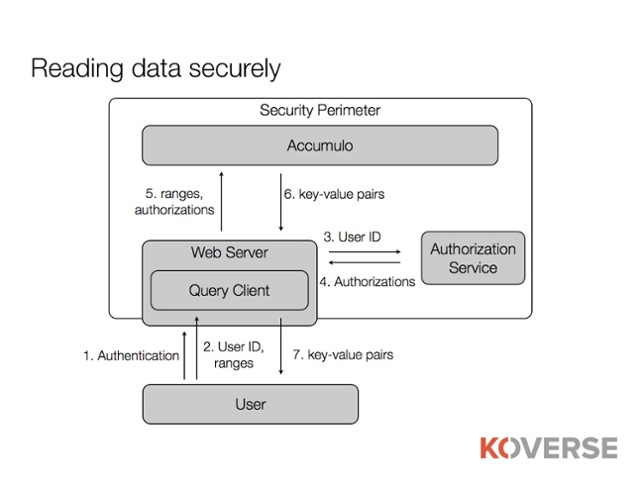
Accumulo enforces cell-level security and developers, building applications on Accumulo, are responsible for writing code to properly apply security labels to data as it is written as well as ensuring that their applications are faithfully passing on the correct user credentials when reading data. This often involves integrating query clients with existing authorization systems.
Developers must also map original data to key-values such that when the key-value pairs are stored and sorted by Accumulo, the sort order supports the kinds of access patterns their applications require. A single Accumulo table can support only a few access patterns efficiently because data can only be sorted one way at a time. To support a wide variety of access patterns, application developers can write code to create tables that contain index entries that point to original data records.
For organizations that want to use Accumulo but don’t want to spend the time or money to engineer applications for storing data, indexing data, querying using high-level languages, properly labeling data, and authorizing queries correctly, Koverse provides the answer.
Data Ingest, Tagging, Profiling and Indexing
Koverse can import data from a range of external sources – relational databases, remote file systems, streaming sources and more – and organize and secure this data into collections.
Upon ingest, Koverse indexes and security tags every field within every record, securely storing the index and the original record. The result is that data ingested into Koverse is automatically searchable and pre-staged for standardized and regulated execution of analytical processing.
Search
Koverse has a very robust and high performance search capability that runs both on data ingested from external sources and data generated from internal analytical processing. Koverse search includes auto-suggest and run across collections or in specific collections, across fields or within specific fields. Searches can be full text, ranges of numbers and dates, or geo-spatial regions. Range queries can span multiple dimensions such as space and time.
All indexes live in Apache Accumulo tables and are secured using the same column visibilities as are applied to original records. This provides massive scalability and assured access control.
Internal Analytics
All analysis in Koverse is performed via transforms. Transforms consist of multi-stage Spark or MapReduce jobs and can be configured to take parameters so that, once an analytical algorithm is developed, it can be reused by non-developers simply via configuration in the Koverse UI.
Because Koverse provides a common data abstraction, transforms can be written once and applied to a variety of input collections. Koverse’s transform API reduces the amount of boilerplate and configuration developers need to do compared to the off-the-shelf Apache Hadoop API, and all transforms can be easily ported to the vanilla Apache Hadoop API if necessary.
Koverse API and SDK
Koverse provides application developers with a REST API, Apache Thrift API and a JavaScript SDK. All aspects of the Koverse platform can be accessed via these methods, allowing data and analytic results from Koverse to be embedded into interactive web applications.
API methods include:
- Query
- Setup workflows
- Control jobs
- Control access
- Administrate
Cell-level security access controls
The Koverse cell-level security model provides high security AND high performance in the same system. Koverse presents a complete suite of security controls: row, column and dataset level visibility and dataset level role-based permissions. These access controls are applied consistently to data across the entire platform with no impact on performance.
Summary
Koverse provides organizations with all of the security, scalability, and performance of Accumulo while drastically reducing the time, cost, and risk of putting Accumulo-based applications into production.
For more information on how Accumulo and Koverse can help you tackle your toughest data challenges, email us at info@koverse.com.