
Search your data: across fields, records, data types and dimensions, all at internet-scale, through a single user interface and API.
In this blog post, we describe how the Koverse Universal Index can be used to make S3 data searchable.
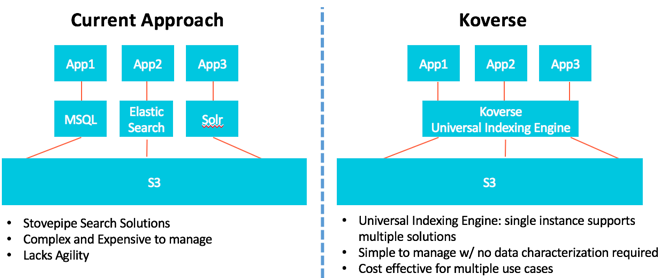
- Enterprises and organizations are collecting and storing more and more data. Huge value and actionable information can be gained from this data if it can be made easily accessible and searchable by business users and analysts throughout an organization.
- Making this data useful, accessible and searchable is a challenge, it requires “hand-loading” it into a search-only tool such as Elastic Search or Solr and takes significant time, effort and expertise for each type of data.
- The Challenge: Big datasets, or data from a large number of different sources, that potentially fall into overlapping security “classifications”, require hand crafting search and access solutions for each individual user group and use case. This is an impossible proposition.
The Koverse Universal Indexing Engine. Koverse was built to give your organization complete visibility and search into your data: across fields, records, data types and dimensions, all at internet-scale, through a single API. Koverse does this by automatically indexing every field of every record of every dataset without the need for ETL or data characterization, and supporting secure multi-level search and access to thousands of end points via a single API. Koverse makes the almost impossible task of supporting multiple use cases across multiple datasets quick and easy. This means that a dataset only has to be ingested and secured once and then directly support multiple applications and use cases. In addition, Koverse gives you the following benefits:
- Access can be granted on a per-dataset level; this means you can drive a range of applications with the same API from very specific narrow data retrieval to “connect the dots” use cases that search across multiple complex datasets.
- Users can search and download subsets of data to put to immediate use in follow on analytics and applications. Users don’t have to depend on IT to sequester and deliver important subsets, they can obtain them on demand.
- Users, if authorized, can upload, search and share data without requiring the assistance of the IT department.
- Koverse can scale to petabytes of data, trillions of records and thousands of datasets in a single instance.
Key Koverse Features
Ingest and Indexing
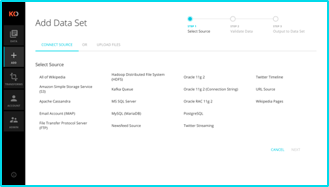 Koverse can import data from a range of external sources – relational databases, remote file systems, streaming sources and more – and organize and secure this data into collections. Upon ingest, Koverse indexes and security tags every field within every record, securely storing the index and the original record. The result is that data ingested into Koverse is automatically searchable and pre-staged for standardized and regulated execution of analytical processing.
Koverse can import data from a range of external sources – relational databases, remote file systems, streaming sources and more – and organize and secure this data into collections. Upon ingest, Koverse indexes and security tags every field within every record, securely storing the index and the original record. The result is that data ingested into Koverse is automatically searchable and pre-staged for standardized and regulated execution of analytical processing.
Search and Download
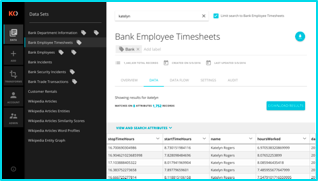 Koverse has a very robust and high performance search capability that runs both on data ingested from external sources and data generated from internal analytical processing. Koverse search includes auto-suggest and run across collections or in specific collections, across fields or within specific fields. Searches can be full text, ranges of numbers and dates, or geo-spatial regions. Range queries can span multiple dimensions such as space and time.
Koverse has a very robust and high performance search capability that runs both on data ingested from external sources and data generated from internal analytical processing. Koverse search includes auto-suggest and run across collections or in specific collections, across fields or within specific fields. Searches can be full text, ranges of numbers and dates, or geo-spatial regions. Range queries can span multiple dimensions such as space and time.
Cell-level Security Access Controls
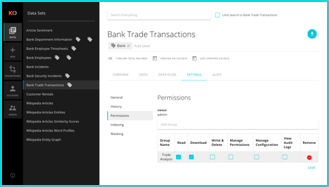 The Koverse cell-level security model provides high security AND high performance in the same system. Koverse presents a complete suite of security controls: row, column and dataset level visibility and dataset level role-based permissions. These access controls are applied consistently to data across the entire platform with no impact on performance.
The Koverse cell-level security model provides high security AND high performance in the same system. Koverse presents a complete suite of security controls: row, column and dataset level visibility and dataset level role-based permissions. These access controls are applied consistently to data across the entire platform with no impact on performance.
For launching multi-node clusters in AWS, Contact us