How It Works
Accelerate your most valuable efforts

Accelerate your most valuable efforts
The Koverse Intelligent Solutions Platform
Koverse Technical Architecture
The Koverse Intelligent Solutions Platform provides one easy-to-use, fully integrated API and UI, protected with cell-level security.
-
Your Solution
Embed intelligent solutions within your organization to gain business insights; connect directly using existing tools or via your custom applications.
-
User Interface, API & SDK
Koverse provides application developers with a REST API, Apache Thrift API and a JavaScript SDK. All aspects of the Koverse Platform can be accessed via these methods, allowing data and analytic results from Koverse to be embedded into interactive web applications. For more developer details click here.
-
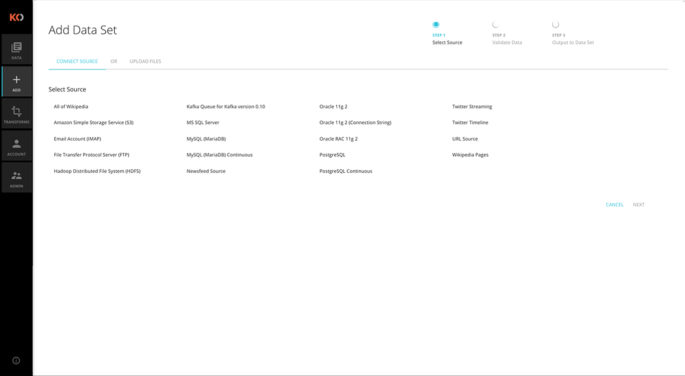
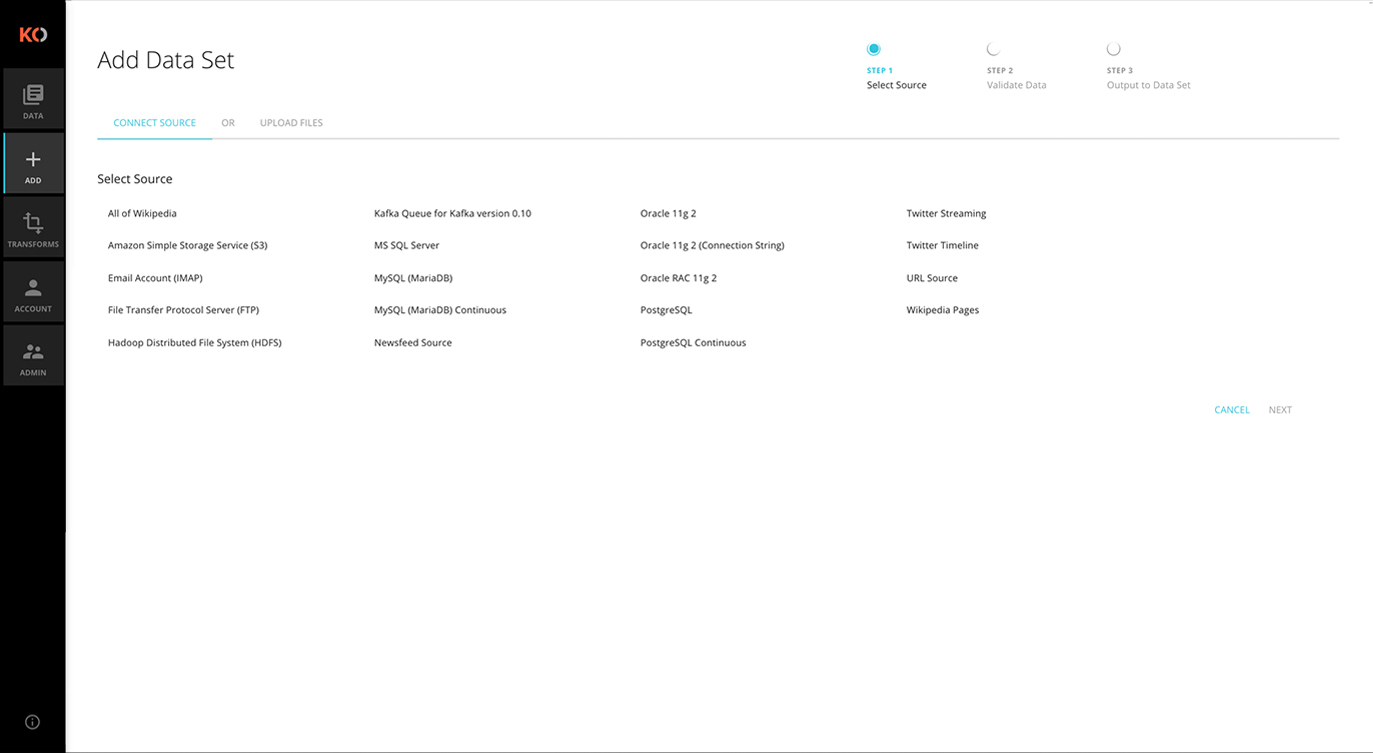
Universal Ingest
The Koverse platform can import data from a range of external sources — relational databases, remote file systems, streaming sources and more. Upon ingest, Koverse indexes and tags every field within every record within every dataset, organizing the data into collections.
The result: securely stored, automatically searchable and pre-staged data for standardized and regulated execution of analytical processing.
Supported data sources include:
- MySQL
- Oracle
- SQL Server
- PostgreSQL
- Cassandra
- Kafka
- Wikipedia
- FTP
- Amazon S3
- HDFS
- IMAP
- Newsfeed
- URL
- Build Your Own
-
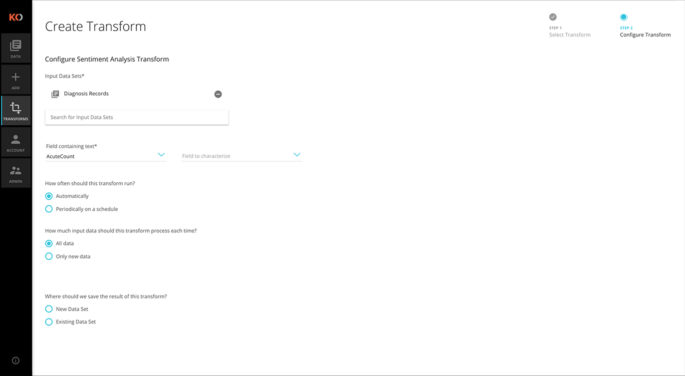
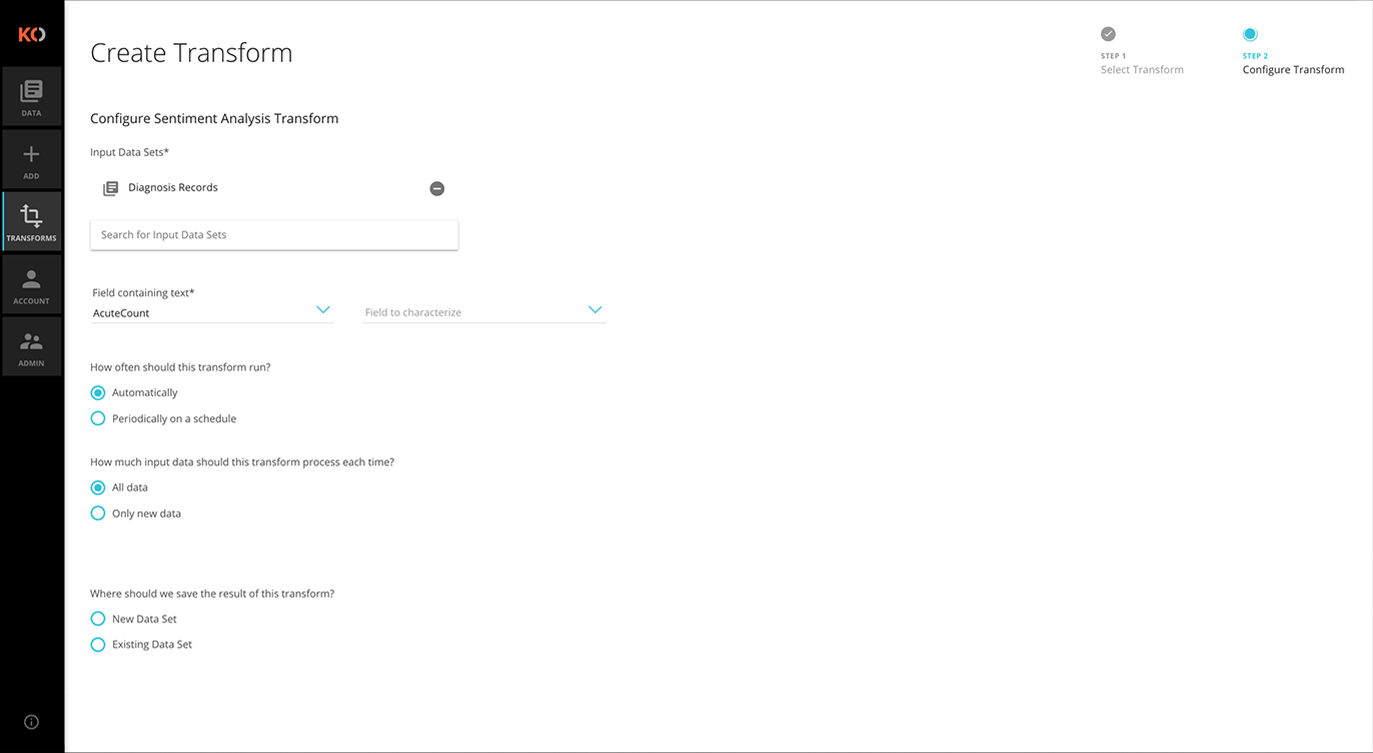
Embedded Analytics
The Koverse platform enables teams to create, develop and deploy unique algorithms to help answer virtually any question put to the data. Once created, algorithms can be reconfigured and reapplied to different datasets and use cases.
All analysis in Koverse is done via transforms. Transforms consist of multi-stage Spark or MapReduce jobs. Because Koverse provides a common data abstraction, transforms can be written once and applied to a variety of input collections, producing the greatest value for all efforts.
-
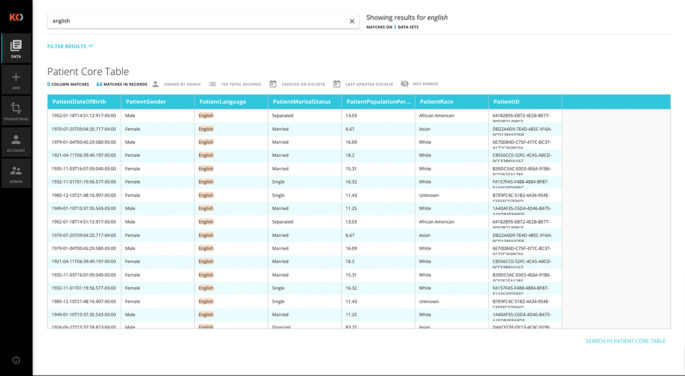
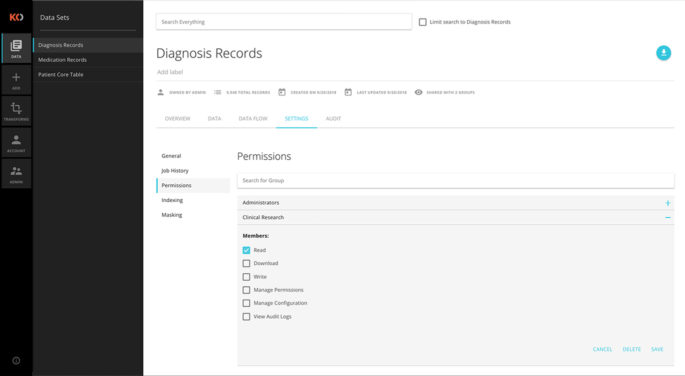
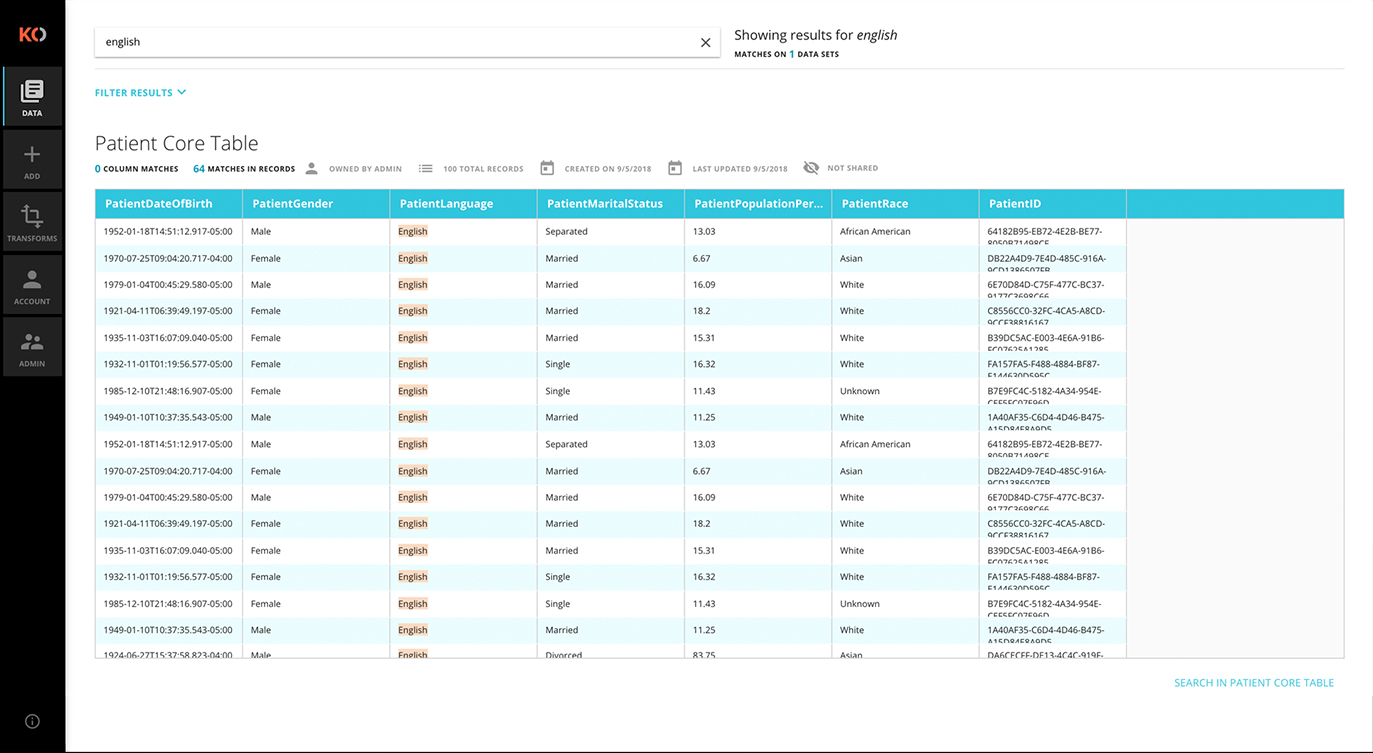
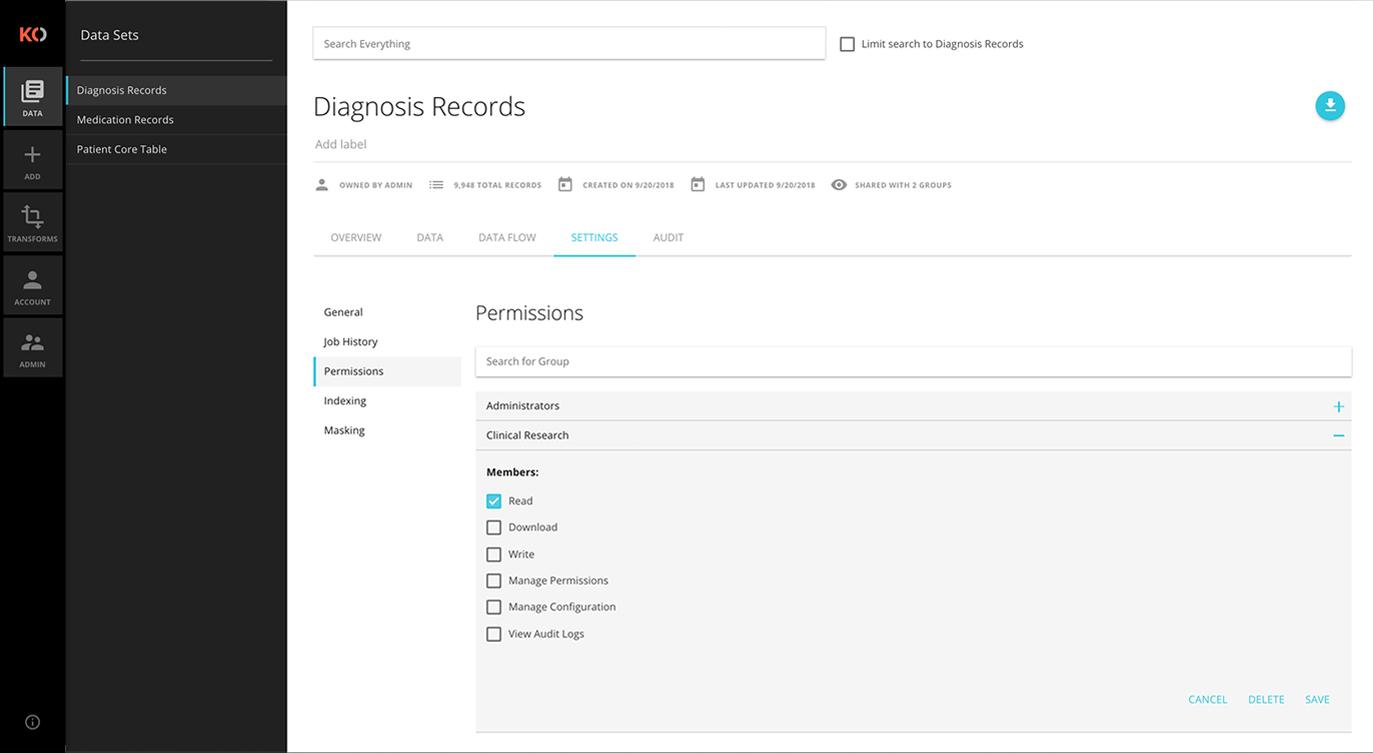
Secure Access & Search
The Koverse Platform’s cell-level security model provides high security and high performance in the same system. Koverse presents a complete suite of security controls: row-, column-, and dataset-level visibility and dataset-level role-based permissions. These access controls are applied consistently to data across the entire platform to keep information secure regardless of how its used. Searches can be done via the Koverse UI or directly by custom solutions via the REST API. Koverse supports both SQL and Lucene search syntax.
-
Record Write, Mapreduce, Spark, Record Read, Spark SQL, Query
Koverse is a full function data platform, providing end-to-end functionality without the need to make and manage multiple copies of data. A unified access layer guarantees scalability and performance and enforces security and audit across ingest, analytics, query and export.
-
Accumulo
Koverse enables teams to work with Accumulo, hassle-free. When organizations need security, performance and scalability, there’s no technology more credible than Accumulo. Koverse is built entirely on the Accumulo database and makes all of Accumulo’s functionality easily accessible. Whether an organization has relied on Accumulo in the past or is just starting out, Koverse is the “easy button” for using it.
-
Hadoop
Accumulo runs entirely on the Hadoop File System and inherits all of the elegant scalability and data processing horsepower of Hadoop.
-
On Premise/Cloud
Koverse provides a flexible delivery model. The Koverse Intelligent Solutions Platform can be deployed on-premise or in the cloud.
Questions? Ready to get started?
We invite you to learn about how Koverse delivers strategic value by efficiently managing complex and sensitive data.